
Deploy Detectron2 models with Triton
Overview
Detectron2 (github) is a PyTorch-based computer vision model library. It’s very popular among DL practitioners and researchers for its highly optimized implementations of many detection and segmentation algorithms.
Triton inference server (github) is a high-performant inference server developed by NVIDIA. It supports most of the popular deep learning frameworks including PyTorch, Tensorflow, and TensorRT.
In this post, we’ll learn how to export a trained Detectron2 model and serve it in production using Triton. You can find the code accompanying this post from this repo
Why use Triton?
Before delving into Triton, we need to know what benefits Triton can bring us compared to other more straightforward serving options (like Flask or FastAPI):
- Supports multiple frameworks: Building an inference system for multiple frameworks from scratch is not easy, it requires careful considerations on decoupling framework-specific processings and resource management. In addition, different frameworks might require different dependency versions, which can lead to conflicts. Triton can run models from different frameworks in the same environment, It can save us a lot of effort for implementing and setting up our own system.
- Concurrent model execution: Triton allows multiple models or multiple instances of a model to run in parallel. Multiple requests can be scheduled to a GPU to be processed simultaneously, this can optimize your hardware utility. Fig 1 shows how two models run in parallel when requests arrive. Requests from a model are processed sequentially by default, but we can control the number of instances for a model to process multiple requests at the same time.
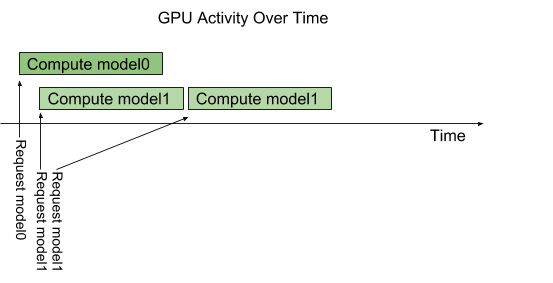
{kind=link}
- Model pipelines: In some use cases, we need to process the data through many steps before obtaining the final results. Triton supports these use cases with Ensemble Models or Business Logic Scripting. For Ensemble Models, we need to define a directed acyclic graph (DAG) to connect the models’ inputs and outputs. Business Logic Scripting is a more flexible way to connect models, it’s basically a Python model (one of the backends supported by Triton) that sends inference requests to other models. Model pipelines can also be used to incorporate preprocessing and postprocessing for a model.
Export a trained model to TorchScript
TorchScript is a program to serialize PyTorch models. A PyTorch model can be exported using TorchScript and then run in other environments without python dependency, such as in C++ with LibTorch library. We’ll try to export it to TorchScript and deploy the exported TorchScript model to the Triton inference server.
First, we need to have a trained model to start with, the Detectron2 repository provides many models and their pre-trained weights. we’ll use the MaskRCNN model with Resnet50 as the model’s backbone (config and weights).
The Detectron2 repository also provides a script to export its models to TorchScript, we’ll use that script with some modifications to export the MaskRCNN model. Make sure you have PyTorch and Detectron2 installed in your environment, you can find the installation instructions for PyTorch and Detection2 from here and here.
Triton requires all tensors to be in the same device. But the implementation from Detectron2 has some tensors in CPU instead of GPU, it’s mentioned in this issue. To workaround the issue without changing the Detectron2 code, we patch the function torch.stack to force it to move the resulting tensor to GPU. In export_model.py, insert the following code:
# imports
...
from unittest.mock import patch
from functools import wraps
import torch
def patch_torch_stack(func):
"""
Patch torch.stack to move its outputs to GPU
"""
orig_stack= torch.stack
def new_stack(*args, **kwargs):
return orig_stack(*args, **kwargs).to('cuda')
@wraps(func)
def wrapper(*args, **kwargs):
with patch("torch.stack", side_effect=new_stack, wraps=orig_stack):
return func(*args, **kwargs)
return wrapper
...
@patch_torch_stack
def export_scripting(torch_model):
...
@patch_torch_stack
def export_tracing(torch_model, inputs):
The decorator basically changes torch.stack(...) to torch.stack(...).to("cuda") so outputs from torch.stack will be automatically moved to GPU.
We’ll need to specify the path to the trained checkpoint for the model we want to export. Let’s make a custom config file with the checkpoint name it custom_mask_rcnn_R_50_FPN_3x.yaml:
_BASE_: "{path-to-configs-folder}/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"
MODEL:
WEIGHTS: "<path-to-checkpoint>"
Before running the script, you may want to check this page for more information on the supported features and limitations of the export script. To export the model to TorchScript, run:
# the input image for --sample-image can be arbitrary
# I picked 000000100008.jpg randomly from the COCO dataset
python export_model.py \
--format torchscript \
--export-method tracing \
--config-file custom_mask_rcnn_R_50_FPN_3x.yaml \
--sample-image 000000100008.jpg \
--output mask_rcnn_outputs
Let’s take a look at the output folder:
mask_rcnn_outputs
├── model.ts --> TorchScript model
├── model_ts_code.txt --> More readable code for the exported model
├── model_ts_IR_inlined.txt
├── model_ts_IR.txt
└── model.txt
Now we have a TorchScript model exported from the MaskRCNN model. Next, we will deploy it with Triton.
Deploy TorchScript model with Triton
The easiest way to get started with Triton is to use the pre-built docker image from NVIDIA. Pull the image:
docker pull nvcr.io/nvidia/tritonserver:22.07-py3
For Triton to recognize the models being served, we need to prepare a model repository with the following structure:
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...
Let’s create a model repository with the exported TorchScript model:
$ mkdir -p models/mask_rcnn
$ cp -r mask_rcnn_outputs models/mask_rcnn/1
$ touch models/mask_rcnn/config.pbtxt
$ tree models
models
└── mask_rcnn
├── 1
│ ├── model.ts
│ ├── model_ts_code.txt
│ ├── model_ts_IR_inlined.txt
│ ├── model_ts_IR.txt
│ └── model.txt
└── config.pbtxt
config.pbtxt is a model configuration that provides information about the model we want to serve. It usually contains the expected inputs/outputs of the model, and which backend to use. A sample config for the MaskRCNN model can be found here. To start an inference server with the Triton docker image, run:
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 --shm-size=1gb \
-v <full-path-to-model-repository>:/models \
nvcr.io/nvidia/tritonserver:22.07-py3 tritonserver --model-repository=/models
Now we have an inference server serving the MaskRCNN model. Let’s make a request to the server to see how it works. You can use this script to send requests to the server (make sure you have tritonclient installed in your environment):
python client.py --model mask_rcnn --image 000000100008.jpg --print-output
Pre-processing and post-processing with Model Pipelines
Triton supports Python backend, which allows us to run python code on the Triton server without writing any C++ code. We’ll explore how to deploy preprocessing and postprocessing code for the deployed MaskRCNN model.
The code for the python models can be found here. Here are what the models do:
- Preprocess: It’s more efficient to transfer image in a compressed format than transfering an image array. The preprocess model takes in a bytes string of the image and decodes it into a numpy array.
- Postprocess: This model takes raw outputs from the MaskRCNN model and prepares final predictions. It basically filters out low-confidence samples and converts the raw masks (direct outputs from the mask head) to masks with the input image size.
The models are quite simple as I just want to demostrate how python models work in Triton. You can extend them further like having resizer or scaler for preprocessing. Next, Let’s create two models for preprocessing and postprocessing in the model repository:
# Create preprocess model
mkdir -p models/preprocess/1
cp python_models/preprocess.py models/preprocess/1/model.py
touch models/preprocess/config.pbtxt
# Create preprocess model
mkdir -p models/postprocess/1
cp python_models/postprocess.py models/postprocess/1/model.py
touch models/postprocess/config.pbtxt
You can find the config files for the models here and here. The python models you want to deploy must follow this structure, it’s better to look through some examples to have some ideas about how python models are implemented in Triton.
Now we have the preprocessing and postprocessing models in the model repository. But we need some dependencies installed to run the models. To make things simple, assume that the python code and the dependencies can work fine with Python 3.8 (which is the python version of the python backend shipped with Triton containers). Pack the dependencies into an archive file using conda:
conda create --name pyenv python=3.8
conda activate pyenv
python -m pip install -r python_models/requirements.txt
conda-pack # This command outputs pyenv.tar.gz
The file “pyenv.tar.gz” is the packed environment to be used later in Triton. Then we need to copy the file to both python models:
cp pyenv.tar.gz models/preprocess
cp pyenv.tar.gz models/postprocess
After having the environment ready, we need to tell Triton to use that environment for the models by setting the “EXECUTION_ENV_PATH” parameter in the config files, it should be already specified in the provided configs. More detailed instructions can be found in the python backend repo.
We already have all individual models set up, now we need to connect the models to make them a pipeline. Basically, a pipeline is a collection of steps where outputs of this step are inputs of the next step. Depending on the use cases, inference pipelines might contain different steps but preprocessing, model inference, and postprocessing are basic steps in most of the pipelines. The following workflow illustrates how it works:
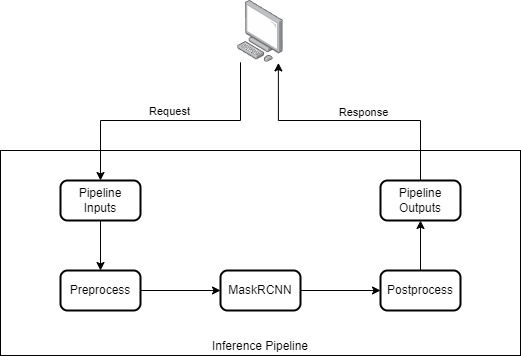
To connect the models, we need to create an ensemble model, for which we define the pipeline and the connection between the models’ inputs and outputs. Run:
# The version folder is empty as the ensemble model has no code or artifact
mkdir -p models/infer_pipeline/1
touch models/infer_pipeline/config.pbtxt
The config for the ensemble model can be found here. The ensemble model starts with the definition of the pipeline’s inputs and outputs. Then a set of steps must be defined. For each step, we must specify mappings between the model’s inputs and outputs, this allows the pipeline to chain multiple models together. Once it’s ready, start the Triton server with the following command or this script:
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 --shm-size=1gb \
-v <full-path-to-model-repository>:/models \
nvcr.io/nvidia/tritonserver:22.07-py3 tritonserver --model-repository=/models
To test the pipeline, we’ll use this client_pipeline script to send requests to the server. Run:
python client_pipeline.py --model infer_pipeline --image 000000100008.jpg --print-output
This is only a simple use case for Ensemble Models with Triton. you can extend the workflow and include more steps in your pipeline if needed. For example, model monitoring is very important in most ML applications but is often overlooked. It keeps track of stats for the predictions, detects if there’s any anomaly occurring, or collects data having high chance of being problematic. We can extend the workflow to support monitoring by having a decouple model monitoring as in the following workflow:
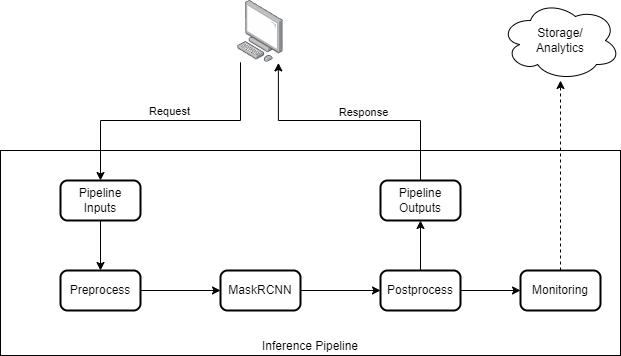
Conclusion
Getting a trained model to production is not straightforward as inference processes are usually very complex in real-world ML problems. In this post, we used Triton to deploy an inference pipeline consisting a MaskRCNN model from Detectron2, preprocessing, and postprocessing. Although it’s a simple use case, we can extent it to build more complicated systems using Ensemble Models as showed in the last section.